
Imagina que contratas al físico más brillante del mundo, un genio que ha memorizado todos los libros de física publicados hasta 2023. Le sientas en una habitación vacía, sin internet y sin libros, y le preguntas: «¿Cuál es el último reporte de ventas de mi empresa de esta mañana?».
El genio te mirará confundido. O peor aún, si es un LLM (Large Language Model), tratará de complacerte inventándose una cifra plausible. Alucinará.
Este es el problema fundamental de la Inteligencia Artificial Generativa, incluso a finales de 2025 con modelos tan avanzados como GPT-5 o Llama 3. Los modelos son razonadores congelados en el tiempo. Tienen un conocimiento general enciclopédico, pero son amnésicos respecto a tus datos privados, tus correos recientes o la documentación técnica que escribiste ayer.
Durante 2023 y 2024, la industria intentó solucionar esto de muchas formas. Primero, aumentando la «ventana de contexto» a 1 millón o 10 millones de tokens (como hizo Google con Gemini). La promesa era: «Simplemente pega todos tus documentos en el prompt». Pero pronto nos dimos cuenta de que eso era insostenible: es lento, cuesta una fortuna por cada pregunta y los modelos sufren del síndrome Lost in the Middle (olvidan lo que está en medio de un texto masivo).
La solución que ha conquistado el mundo empresarial y técnico en 2026 no es hacer el modelo más grande, sino hacerlo más listo a la hora de buscar. La solución es RAG (Retrieval-Augmented Generation).
En esta guía monumental, vamos a diseccionar la arquitectura que separa a los juguetes de IA de las herramientas empresariales reales. Aprenderás a construir un sistema que no solo «charla», sino que cita fuentes, respeta la privacidad y conoce tus datos mejor que tú mismo.

Capítulo 1: ¿Qué es RAG y por qué es la arquitectura reina en 2026?
El término RAG fue acuñado por Patrick Lewis (investigador de Meta) en 2020, pero no fue hasta la explosión de ChatGPT que se convirtió en el estándar de facto.
1.1 Definición Técnica vs. La Analogía del Examen
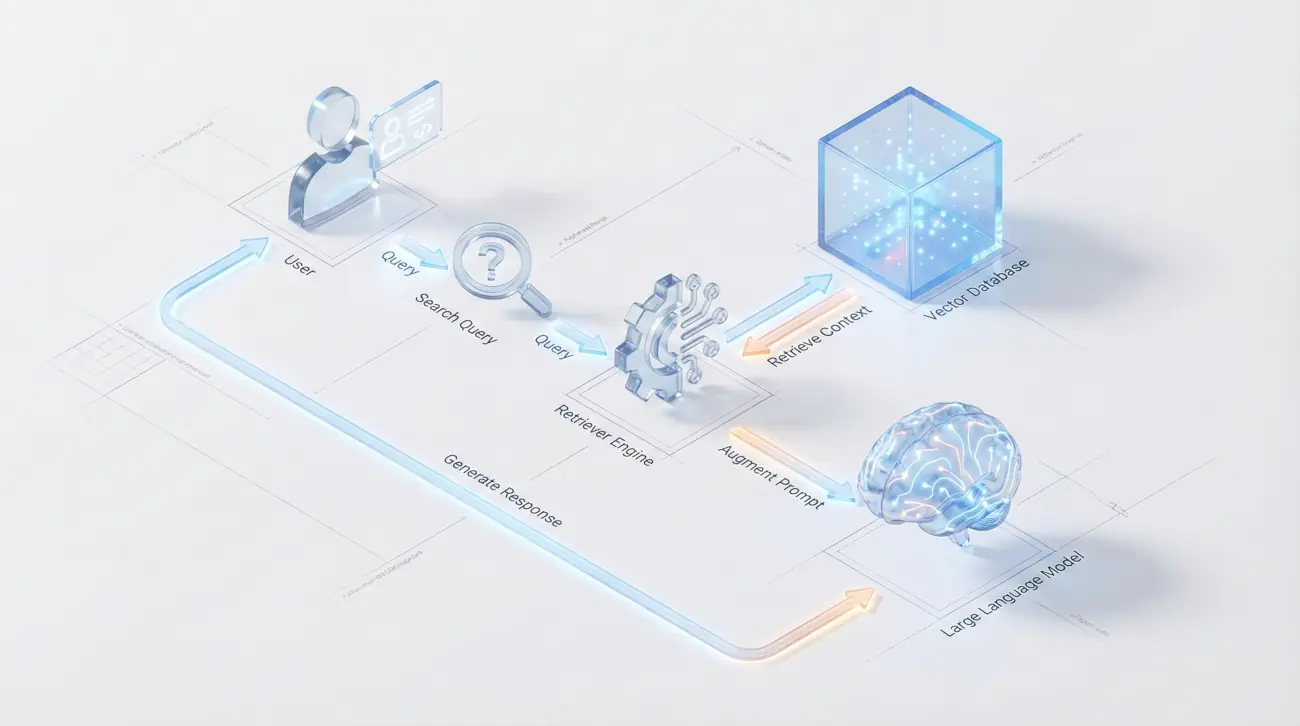
En términos técnicos, RAG es un patrón de diseño de software que optimiza la salida de un LLM permitiéndole consultar una base de conocimientos autorizada externa a sus datos de entrenamiento antes de generar una respuesta.
Pero usaremos la analogía del Examen a Libro Abierto:
-
ChatGPT estándar (sin RAG): Es un estudiante haciendo un examen de memoria. Sabe mucho, pero si no se acuerda de un dato exacto, se lo inventa para rellenar el hueco.
-
RAG: Es ese mismo estudiante, pero con permiso para abrir el libro de texto (tus datos), buscar la página exacta, leer el párrafo relevante y luego redactar la respuesta basándose únicamente en lo que acaba de leer.
La magia del RAG en 2026 es que ese «libro de texto» puede ser cualquier cosa: millones de PDFs, una base de datos SQL, tu Notion, Slack, o incluso transcripciones de reuniones de Zoom en tiempo real.
1.2 RAG vs. Fine-Tuning: La Gran Confusión
A día de hoy, sigo viendo a CTOs y desarrolladores cometer el error de gastar miles de dólares en Fine-Tuning (ajuste fino) esperando que el modelo aprenda nuevos datos. Aclaremos esto para siempre:
-
Fine-Tuning es para la FORMA (Personalidad/Habilidad): Si quieres que tu IA hable como un pirata, escriba código en un formato JSON específico de tu empresa o resuma textos médicos con jerga profesional, haces Fine-Tuning. Estás cambiando las conexiones neuronales del modelo para enseñarle un comportamiento.
-
RAG es para el FONDO (Conocimiento/Datos): Si quieres que tu IA sepa qué stock queda en el almacén B o qué dice la cláusula 4.2 del contrato con el Cliente X, usas RAG.
La Regla de Oro: Si la información cambia frecuentemente (precios, noticias, stock), el Fine-Tuning es inútil, porque tendrías que reentrenar el modelo cada día. El RAG, en cambio, solo necesita actualizar la base de datos documental, lo cual es instantáneo y barato.
1.3 La Evolución: De RAG Naive a Agentic RAG
Lo que hacíamos en 2023 se conoce hoy como Naive RAG (RAG Ingenuo): trocear texto, buscar por similitud y enviarlo al LLM. Funcionaba bien para demos, pero fallaba en producción.
En 2026, estamos en la era del RAG Modular y Agéntico:
-
Naive RAG: Búsqueda simple directa.
-
Advanced RAG: Añade pre-procesamiento (limpieza de datos) y post-procesamiento (Reranking de resultados para asegurar que lo más relevante va primero).
-
Modular RAG: Usa múltiples módulos que pueden reescribir la consulta del usuario para buscar mejor, o buscar en múltiples fuentes a la vez.
-
Agentic RAG (El Estándar 2026): El LLM actúa como un agente autónomo. No solo busca y responde. Evalúa: «¿La información que encontré es suficiente? No. Entonces voy a hacer otra búsqueda con términos diferentes, o voy a consultar esta API de SQL, y luego consolidaré la respuesta»..

Capítulo 2: La Ciencia detrás de la Magia: Vectores y Embeddings
Para entender cómo una máquina puede «buscar conceptos» y no solo «palabras clave» (como hacía el antiguo Ctrl+F), debemos descender al sótano de las matemáticas: el Espacio Vectorial.
2.1 ¿Cómo entiende una máquina el significado? (Espacios Latentes)
Los ordenadores no entienden letras ni palabras; solo entienden números. El proceso de Embedding (incrustación) consiste en tomar un trozo de texto (una palabra, una frase o un párrafo) y convertirlo en una lista larga de números decimales (un vector).
Por ejemplo, la palabra «Rey» podría convertirse en [0.2, 0.9, -0.4...]. La magia ocurre porque estos números no son aleatorios. Representan coordenadas en un espacio multidimensional (a veces miles de dimensiones).
En este espacio geométrico, los conceptos que significan cosas similares están físicamente cerca.
-
Si trazamos una línea desde «Rey» a «Hombre» y aplicamos esa misma dirección a «Mujer», llegamos matemáticamente cerca de «Reina».
-
La frase «Mi smartphone no tiene batería» tendrá un vector muy cercano a «Necesito un cargador para el móvil», aunque no compartan casi ninguna palabra.
Esto es la Búsqueda Semántica. El sistema RAG calcula la distancia (generalmente usando la Similitud del Coseno) entre la pregunta del usuario y tus millones de documentos, recuperando aquellos que están «cerca» en significado, no solo en sintaxis.
2.2 Modelos de Embeddings SOTA (State of the Art) en 2026
La calidad de tu RAG depende en un 50% de tu modelo de Embeddings. Si el modelo es malo, la búsqueda será mala, y el LLM responderá basura (Garbage In, Garbage Out).
A finales de 2025, el panorama se divide en tres:
-
Propietarios de Alto Rendimiento:
-
OpenAI
text-embedding-3-large(y versiones posteriores): Sigue siendo el estándar por facilidad de uso y dimensiones dinámicas (puedes acortar el vector sin perder mucha precisión). -
Cohere Embed v3: Especialmente potente porque fue entrenado específicamente para tareas de RAG y recuperación, no solo similitud de frases. Tiene un rendimiento multilingüe excepcional.
-
-
Open Source y Locales (La Tendencia 2026):
-
El leaderboard MTEB (Massive Text Embedding Benchmark) es la biblia aquí. Modelos como BGE-M3 (BAAI General Embedding) o la serie E5 de Microsoft/Alibaba dominan.
-
La ventaja es que puedes correr estos modelos en tu propia infraestructura (On-Premise) con librerías como
SentenceTransformers, garantizando que tus datos nunca salgan de tu servidor durante la fase de vectorización.
-
-
Embeddings Matryoshka: Una innovación clave de 2025. Permiten entrenar un solo modelo que produce vectores que pueden truncarse (cortarse) a diferentes tamaños según necesites velocidad o precisión, sin necesidad de reentrenar.
Capítulo 3: El Stack Tecnológico Moderno (Herramientas 2026)
Ya conocemos la teoría. Ahora vamos a llenar el carrito de la compra. ¿Qué software necesitamos para montar esto hoy en día? El ecosistema se ha consolidado mucho respecto al caos de 2023.
3.1 Orquestadores: LangChain vs. LlamaIndex (¿Quién ganó?)
Durante años hubo una guerra fría entre estos dos frameworks.
-
LangChain: Empezó como una navaja suiza para todo lo relacionado con LLMs. Es inmenso, a veces caótico, pero tiene integraciones con absolutamente todo. En 2026, LangGraph (su módulo para crear agentes cíclicos) es el estándar para flujos complejos.
-
LlamaIndex (antes GPT Index): Se especializó desde el día uno en datos. Su gestión de la ingesta, el chunking y la indexación es superior si tu foco es puramente RAG sobre grandes volúmenes de datos desestructurados.
Veredicto 2026:
-
Si tu app es un agente complejo que usa herramientas, navega por internet y toma decisiones: LangChain / LangGraph.
-
Si tu app es un buscador inteligente sobre miles de PDFs y excels corporativos: LlamaIndex.
-
Tendencia «No-Framework»: Muchos ingenieros senior están optando por escribir el flujo en Python puro (
openaiSDK +pydantic) para tener control total y evitar las abstracciones excesivas, usando los frameworks solo para partes específicas.
3.2 Bases de Datos Vectoriales (Vector Stores)
Donde guardas tus vectores. Aquí ha habido una limpieza de mercado brutal.
-
Las Nativas (Specialized):
-
Pinecone: El líder serverless. En 2026 lanzaron su arquitectura «Serverless» real, donde pagas solo por lectura/escritura y almacenamiento, sin provisionar «pods». Es la opción más fácil para empezar y escalar.
-
Weaviate & Milvus: Las opciones open-source pesadas. Ideales si quieres autohospedar tu base de datos en Kubernetes con escalabilidad masiva (millones de vectores).
-
ChromaDB: La favorita para desarrollo local y notebooks. Simple, corre en memoria o en disco local.
-
-
Las Integradas (La opción pragmática):
-
pgvector (PostgreSQL): El gran ganador silencioso. Si tu empresa ya usa Postgres, no necesitas contratar una base de datos nueva. Instalas la extensión
pgvectory listo. En 2025 optimizaron su indexación HNSW haciéndola competitiva con las nativas. Para el 90% de las empresas, esto es suficiente. -
MongoDB Atlas Vector Search: Si tu stack es MERN, Mongo ya trae búsqueda vectorial nativa.
-
3.3 LLMs: El Cerebro Generador
Finalmente, ¿quién redacta la respuesta?
-
Los Gigantes (API): GPT-5 (o GPT-4o refinado) y Claude 3.5 Opus siguen siendo los reyes del razonamiento. Si necesitas que el bot siga instrucciones muy complejas y razone sobre los datos recuperados, estos son la opción segura. Su precio ha bajado drásticamente (casi 10x menos que en 2023).
-
Los Locales (Open Weights): Aquí está la revolución de la privacidad. Llama 3 (y versiones posteriores) de Meta y Mistral han alcanzado un nivel donde un modelo de 8B o 70B parámetros, corriendo en tus propias GPUs, puede hacer RAG perfectamente bien.
-
SLMs (Small Language Models): Modelos minúsculos como Phi-4 (Microsoft) o versiones destiladas de Llama, diseñados para correr en CPUs o dispositivos móviles, que son increíblemente buenos en tareas RAG simples si el contexto es claro.

Capítulo 4: Tutorial Fase 1 - Ingesta y Chunking (El secreto del éxito)
La mayoría de los proyectos RAG fallan aquí. Si le das basura a la base de datos, recuperarás basura (Garbage In, Garbage Out). No puedes simplemente meter un PDF de 500 páginas en la base de datos como un solo bloque.
4.1 Estrategias de Chunking en 2026
El «Chunking» es el arte de dividir tus documentos en trozos digeribles.
-
Fixed-size Chunking (Obsoleto): Cortar cada 500 caracteres. Es rápido pero estúpido. Puedes cortar una frase por la mitad y perder el significado.
-
Recursive Character Split: Mejor. Intenta cortar por párrafos, luego por frases, luego por palabras.
-
Semantic Chunking (El Estándar 2026): Usamos un modelo de IA pequeño para leer el documento y cortar solo cuando el tema cambia. Si un párrafo habla de «Precios» y el siguiente de «Garantía», el modelo corta ahí. Esto garantiza que cada chunk sea temáticamente puro.
4.2 Limpieza y Metadatos
Un vector sin contexto es inútil. En 2026, el Metadata Filtering es vital. Cuando guardas un chunk, no guardas solo el texto. Guardas:
-
fuente: «manual_empleado_v2.pdf» -
fecha: «2026-01-10» -
departamento: «RRHH» -
pagina: 12
Esto permite que, luego, el LLM pueda filtrar: «Busca solo en documentos de RRHH publicados después de 2025».
📝 Código: Ingesta Inteligente
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
# 1. Cargar el documento
loader = PyPDFLoader(«manual_operaciones_2026.pdf»)
docs = loader.load()
# 2. Chunking (Estrategia Recursiva con solapamiento)
# chunk_overlap=100 asegura que no perdemos contexto en los cortes
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
add_start_index=True
)
splits = text_splitter.split_documents(docs)
# 3. Vectorización y Almacenamiento (Persistente)
# Usamos embeddings de OpenAI (o podrías usar HuggingFace local)
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(model=«text-embedding-3-small»),
persist_directory=«./chroma_db»
)
print(f»¡Ingestado! Se crearon {len(splits)} fragmentos vectoriales.»)

Capítulo 5: Tutorial Fase 2 - Retrieval (Recuperación) y Reranking
Ahora que tenemos los datos, hay que buscarlos. Pero la búsqueda vectorial (similitud del coseno) no es perfecta. A veces, «Código 404» y «Error de Servidor» no están matemáticamente cerca si el modelo de embeddings no fue entrenado con datos técnicos.
5.1 Hybrid Search: Lo mejor de dos mundos
En 2026, ningún sistema serio usa solo vectores. Usamos Búsqueda Híbrida:
-
Dense Retrieval (Vectores): Encuentra similitudes conceptuales («Gato» <-> «Felino»).
-
Sparse Retrieval (BM25/Keyword): Encuentra coincidencias exactas de palabras clave («Error 503»).
Combinamos ambos resultados usando un algoritmo llamado RRF (Reciprocal Rank Fusion).
5.2 El Truco Maestro: Reranking (Reordenamiento)
La búsqueda vectorial es rápida pero imprecisa. Puede traerte 50 documentos «parecidos». Aquí entra el Cross-Encoder Reranker (como Cohere Rerank o bge-reranker). Es un modelo más lento y potente que lee la pregunta del usuario Y los 50 documentos recuperados, y los reordena poniendo los verdaderamente relevantes arriba del todo.
Flujo: Recupera 50 chunks (rápido) -> Rerankea y quédate con los 5 mejores (lento pero preciso) -> Envía al LLM.
📝 Código: Configurando el Retriever con Rerank
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
from langchain_community.vectorstores import Chroma
# Cargamos la DB existente
vectorstore = Chroma(persist_directory=«./chroma_db», embedding_function=OpenAIEmbeddings())
# Retriever Base (busca 20 documentos por similitud)
base_retriever = vectorstore.as_retriever(search_kwargs={«k»: 20})
# Capa de Reranking (El filtro de calidad)
compressor = CohereRerank(model=«rerank-english-v3.0», top_n=5) # Solo pasan los 5 mejores
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# Probamos
docs = compression_retriever.invoke(«¿Cuál es la política de vacaciones?»)
for doc in docs:
print(f»Relevancia: {doc.metadata[‘relevance_score’]} – Texto: {doc.page_content[:100]}…»)
Capítulo 6: Tutorial Fase 3 - Generación y Prompt Engineering para RAG
Ya tenemos los 5 fragmentos de texto perfectos. Ahora hay que dárselos al LLM para que responda al usuario. Aquí entramos en el terreno del Prompt Engineering.
6.1 Anatomía de un Prompt RAG
No basta con decir «Responde». Debes blindar al modelo contra alucinaciones.
El Prompt de Sistema estándar en 2026 se parece a esto:
«Eres un asistente experto de soporte técnico. Responderás a la pregunta del usuario ÚNICAMENTE basándote en el siguiente CONTEXTO recuperado. Si la respuesta no está en el contexto, di textualmente: ‘Lo siento, no tengo información sobre eso en mis documentos’. No inventes nada. Cita el nombre del documento del que sacaste la información.»
CONTEXTO: {contexto_recuperado}
PREGUNTA: {pregunta_usuario}
📝 Código: El Bucle Final (RAG Chain)
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# El Cerebro (LLM)
llm = ChatOpenAI(model=«gpt-4o», temperature=0) # Temp 0 para máxima precisión
# El Prompt Blindado
system_prompt = (
«Usa el siguiente contexto para responder a la pregunta. «
«Si no sabes la respuesta, di que no lo sabes. «
«Usa tres oraciones máximo y sé conciso.»
«\n\n»
«{context}»
)
prompt = ChatPromptTemplate.from_messages([
(«system», system_prompt),
(«human», «{input}»),
])
# Crear la cadena
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(compression_retriever, question_answer_chain)
# Ejecutar
response = rag_chain.invoke({«input»: «¿Cuántos días de teletrabajo tengo?»})
print(response[«answer»])

Capítulo 7: Nivel Dios - GraphRAG y Agentes
Si has llegado hasta aquí, tienes un sistema RAG «clásico» que funciona mejor que el 90% de los bots de 2024. Pero estamos en 2026. ¿Qué pasa cuando la pregunta requiere conectar puntos distantes?
Ejemplo: «Compara la estrategia de ventas de 2022 con la de 2025 y dime si los riesgos de ciberseguridad mencionados en el anexo B afectaron al margen de beneficios.»
Un RAG vectorial fallará aquí. Necesita entender relaciones complejas.
7.1 GraphRAG: La Revolución de Microsoft
GraphRAG combina bases de datos vectoriales con Grafos de Conocimiento (Knowledge Graphs). En lugar de trozos de texto sueltos, el sistema extrae «Entidades» (Personas, Lugares, Conceptos) y «Relaciones» (Es jefe de, Afecta a, Ocurrió antes de).
Cuando buscas, el sistema navega por el grafo. Puede ver que «Estrategia 2022» está conectada con «Bajada de precios», y que eso afectó al nodo «Beneficios». GraphRAG permite el razonamiento multi-salto.
7.2 Agentic RAG: El Cerebro Autónomo
En lugar de un flujo lineal (Buscar -> Responder), usamos Agentes. El LLM se convierte en un orquestador que tiene herramientas.
-
Usuario: «¿Cuál es el saldo de mi cuenta y cuál fue el último cargo?»
-
Agente (Pensamiento): «Necesito dos datos. Primero consultaré la herramienta
BaseDatos_Saldo. Luego consultaréBaseDatos_Transacciones. Luego sumaré si hace falta.» -
Acción: Ejecuta consultas SQL o vectoriales por separado.
-
Respuesta: Consolida la información.
Frameworks como LangGraph permiten definir estos flujos cíclicos donde el bot puede «reflexionar» y corregirse a sí mismo antes de responder.
Capítulo 8: Costes, Privacidad y Despliegue en Producción
Antes de lanzar, hablemos de la realidad empresarial.
La Factura a Fin de Mes
-
Embeddings: Es lo más barato. Vectorizar la Wikipedia entera con OpenAI cuesta menos de $500.
-
Vector DB: Pinecone o Weaviate gestionados cuestan desde $70/mes hasta miles, dependiendo del volumen.
pgvectores gratis si ya tienes Postgres. -
LLM (Generación): Aquí está el coste real. Cada pregunta consume tokens de entrada (tu contexto recuperado) y de salida.
-
Estrategia de ahorro 2026: Usa Prompt Caching (cachear el contexto si es repetitivo) y modelos pequeños (Llama 3 8B) para preguntas simples, enrutando solo las complejas a GPT-5.
-
Privacidad: RAG Local
Para sectores regulados (legal, salud), enviar datos a la nube es inviable. En 2026, desplegamos RAG 100% On-Premise:
-
Ingesta: Scripts de Python locales.
-
DB: ChromaDB en disco local.
-
LLM: Ollama o vLLM sirviendo un modelo Llama 3 cuantizado (Q4_K_M) que corre en una tarjeta gráfica de consumo (RTX 4090).
-
Resultado: Cero datos salen de tu edificio. Cero coste por token.

Conclusión: El Futuro de la Memoria Artificial
Hemos recorrido un largo camino. Desde entender por qué los LLMs alucinan, hasta construir un sistema capaz de leer, filtrar, reordenar y sintetizar tu información privada con precisión quirúrgica.
El RAG no es una moda pasajera; es la arquitectura que permite que la IA sea útil en el mundo real. En el futuro inmediato, la línea entre «buscar» y «generar» desaparecerá. Los sistemas operativos de 2027 integrarán RAG nativamente (tu sistema operativo sabrá todo lo que has visto en tu pantalla y podrá responder preguntas sobre ello).
Pero no hace falta esperar. Con las herramientas que has visto hoy —LangChain, Chroma, Modelos Locales y GraphRAG— tienes el poder de construir ese futuro ahora mismo. Tus datos están esperando hablar. ¿Les darás voz?
💬 Preguntas y Respuestas (FAQ)
1. ¿Cuál es la diferencia real entre RAG y Fine-Tuning y cuál debo elegir?
1. ¿Cuál es la diferencia real entre RAG y Fine-Tuning y cuál debo elegir?
Esta es la duda número uno. El Fine-Tuning (ajuste fino) es para enseñar al modelo cómo hablar o cómo razonar en un formato específico (ej. hablar como un médico o responder en JSON). No es bueno para enseñarle nuevos conocimientos. El RAG es para darle al modelo memoria y datos actualizados. Si quieres que tu bot responda sobre tus manuales de PDF de 2026, necesitas RAG. Si quieres que hable con el tono de tu marca, necesitas Fine-Tuning. A menudo, la mejor solución es un híbrido.
2. Con ventanas de contexto de 1 millón de tokens (Gemini/GPT-4o), ¿sigue siendo necesario el RAG?
2. Con ventanas de contexto de 1 millón de tokens (Gemini/GPT-4o), ¿sigue siendo necesario el RAG?
Absolutamente. Aunque puedas meter un libro entero en el prompt («Context Stuffing»), surgen tres problemas: Coste (pagas por cada token de entrada, cada vez que preguntas), Latencia (tarda mucho en procesar 1M de tokens) y «Lost in the Middle» (los modelos tienden a olvidar información que está en medio de un contexto muy largo). RAG sigue siendo la forma más eficiente, barata y precisa de recuperar información específica de grandes corpus de datos.
3. ¿Qué es GraphRAG y por qué todo el mundo habla de ello en 2026?
3. ¿Qué es GraphRAG y por qué todo el mundo habla de ello en 2026?
El RAG vectorial tradicional busca por similitud semántica, pero falla en conectar puntos distantes. Si preguntas «¿Cómo influyó la política de precios de 2023 en la crisis de stock de 2025?», un RAG normal puede fallar. GraphRAG utiliza Gráficos de Conocimiento (nodos y relaciones) para entender la estructura y las conexiones entre entidades, permitiendo un razonamiento mucho más profundo y «multi-salto» (multi-hop) que los vectores simples no pueden lograr.
4. ¿Cuánto cuesta mantener un sistema RAG en producción?
4. ¿Cuánto cuesta mantener un sistema RAG en producción?
Depende de tu tráfico y stack. Tienes tres costes: Almacenamiento Vectorial (Pinecone/Weaviate cobran por volumen, aunque hay opciones open source como ChromaDB), Embeddings (barato, se paga una vez al ingerir), y Generación LLM (el más caro, pagas por cada pregunta/respuesta). En 2026, usar modelos locales pequeños (SLMs) como Llama 3 8B para la generación reduce el coste casi a cero si tienes tu propio hardware, pagando solo electricidad.
5. ¿Es seguro enviar mis datos privados a OpenAI/Anthropic con RAG?
5. ¿Es seguro enviar mis datos privados a OpenAI/Anthropic con RAG?
En una arquitectura RAG estándar, solo envías al LLM los fragmentos de texto (chunks) relevantes para la pregunta del usuario, no toda tu base de datos. Sin embargo, sigues enviando datos. Para privacidad total (banca, salud), la tendencia en 2026 es usar RAG Local: un modelo de embeddings local (HuggingFace) y un LLM local (Ollama/vLLM) corriendo en tus propios servidores (On-Premise), garantizando que ningún dato salga de tu red.
6. ¿Qué es el "Chunking" y por qué es la parte más crítica?
6. ¿Qué es el "Chunking" y por qué es la parte más crítica?
El chunking es cómo divides tus documentos antes de guardarlos. Si cortas una frase por la mitad, el buscador semántico perderá el contexto. Si los trozos son muy grandes, confundes al LLM con «ruido». Estrategias avanzadas como el «Parent-Child Chunking» (buscar en trozos pequeños pero enviar al LLM el trozo grande padre) o el «Semantic Chunking» (cortar cuando cambia el tema, no por número de caracteres) son lo que diferencia un bot mediocre de uno excelente.
7. ¿Cómo evito que mi RAG alucine y se invente respuestas?
7. ¿Cómo evito que mi RAG alucine y se invente respuestas?
El RAG reduce alucinaciones, pero no las elimina. Para mitigarlas: 1) Usa un Prompt de Sistema estricto («Responde solo basándote en el contexto proporcionado. Si no lo sabes, di que no lo sabes»). 2) Implementa Citas: obliga al modelo a decirte de qué documento sacó la info. 3) Usa métricas de evaluación como RAGAS para testear la fidelidad de la respuesta frente al contexto recuperado.
8. ¿Qué base de datos vectorial debo usar en 2026?
8. ¿Qué base de datos vectorial debo usar en 2026?
Para prototipos, ChromaDB o FAISS (locales y gratis). Para producción escalable, Pinecone (serverless, muy fácil) o Weaviate (híbrido potente). Si ya usas PostgreSQL en tu empresa, la extensión pgvector es la opción ganadora por simplicidad de mantenimiento, ya que no necesitas una infraestructura nueva separada.
9. ¿Qué es el "Hybrid Search" y por qué es mejor que la búsqueda vectorial sola?
9. ¿Qué es el "Hybrid Search" y por qué es mejor que la búsqueda vectorial sola?
La búsqueda vectorial es genial para conceptos («fruta» encuentra «manzana»), pero mala para exactitudes («código de error 504»). La búsqueda híbrida combina Vectores (semántica) con BM25 (búsqueda tradicional por palabras clave). Un sistema RAG profesional en 2026 siempre usa búsqueda híbrida junto con un paso de Reranking (reordenar los resultados con un modelo especializado) para obtener lo mejor de ambos mundos.
10. ¿Puedo hacer RAG con imágenes y tablas (Multimodal)?
10. ¿Puedo hacer RAG con imágenes y tablas (Multimodal)?
Sí. En 2026, el RAG Multimodal es estándar. Puedes procesar PDFs que contienen gráficos y tablas. Tienes dos enfoques: 1) Usar modelos como GPT-4o para describir las imágenes en texto y vectorizar ese texto. 2) Usar modelos de embeddings multimodales (como CLIP o SigLIP) que pueden poner imágenes y texto en el mismo espacio vectorial, permitiendo buscar imágenes mediante texto y viceversa.